

Soul全栈加速技术突破,SoulXFlashTalk实现14B模型亚秒级响应



独家抢先看
大参数量模型与实时性难以兼顾,一直是AI数字人领域的核心矛盾,14B级别大模型往往面临推理慢、延迟高、硬件要求苛刻等问题,难以落地实际场景。Soul App AI团队通过架构创新与全链路优化,成功开源SoulXFlashTalk模型,在保持140亿参数强大建模能力的同时,实现0.87秒亚秒级延时与32fps高帧率运行。该模型依托专为8H800节点设计的全栈加速引擎,结合多项算法创新,破解大模型实时运行难题,为行业提供高性能、可落地的技术方案。
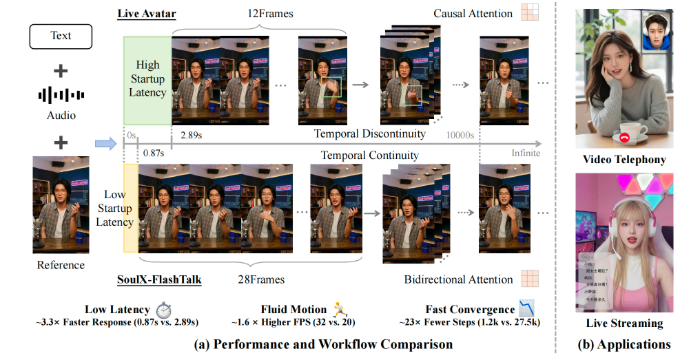
SoulXFlashTalk的低延迟高性能,核心来自全栈加速引擎的系统化优化。团队针对实时推理进行全方位改造,首先采用混合序列并行技术,整合Ulysses与Ring Attention两种并行策略,使单步推理速度提升约5倍,大幅降低模型计算耗时。在算子层面,选用针对Hopper架构优化的FlashAttention3,通过异步执行模式,进一步减少20%的端到端延迟,提升整体响应速度。针对VAE处理瓶颈,模型引入3D VAE并行化与空间切片并行解码策略,实现VAE处理速度5倍提升,有效缓解视频解码延迟。最后通过torch.compile完成全流程图融合与内存优化,实现计算、传输、存储全链路效率升级。
从推理架构流程来看,SoulXFlashTalk各模块协同高效运转,音频预处理、运动帧编码、DiT模型推理、VAE解码等环节均经过极致精简优化。数据显示,模型各模块耗时大幅压缩,从启动到输出首帧视频仅需0.87秒,单轮循环推理保持高效稳定,为连续视频生成提供保障。同时,模型采用双向注意力机制,替代传统单向结构,避免时间信息丢失与误差累积,不仅提升生成质量,还进一步优化推理效率,让大模型在长序列生成中依旧保持低延迟运行。
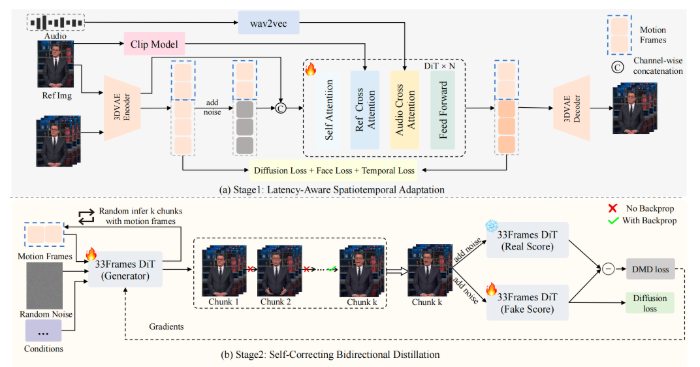
训练流程示意图
在保证速度的同时,SoulXFlashTalk并未牺牲生成质量。模型采用两阶段训练策略,先通过延迟感知时空适配完成基础微调,再以自纠正双向蒸馏实现加速与纠错,平衡推理速度与画面保真度。0.87秒亚秒级延时让大模型数字人具备即时交互能力,可快速响应视频对话、直播弹幕、客服咨询等需求;32fps高帧率确保画面流畅无卡顿,远超行业实时标准;自纠正技术保障画面稳定清晰,全身动作生成提升交互真实感,实现速度与效果双优。
经专业数据集测试,SoulXFlashTalk在长短视频任务中均保持领先性能,各项指标优于Ditto、LiveAvatar等主流模型,充分证明全栈加速方案的有效性。该模型可广泛应用于电商直播、短视频制作、AI教育、智能客服等多元场景,解决传统大模型无法实时落地的痛点。Soul通过此次开源,将先进加速技术共享给行业,继SoulXPodcast之后再献重磅成果,未来将持续深耕推理优化与交互技术,以开源生态助力全球开发者,推动AI+社交领域实现更高效率、更低成本的技术落地。
免责声明:本文为企业宣传商业资讯,仅供用户参考,如用户将之作为消费行为参考,凤凰网敬告用户需审慎决定。



